The aim in this activity is to investigate some more properties of the 2D Fourier Transform (FT) and to apply these properties in enhancing images.
A. Anamorphic property of FT of different 2D patterns
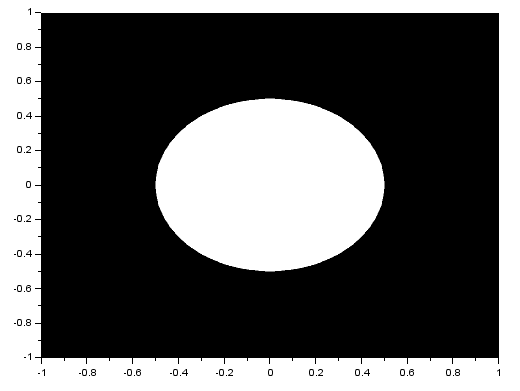
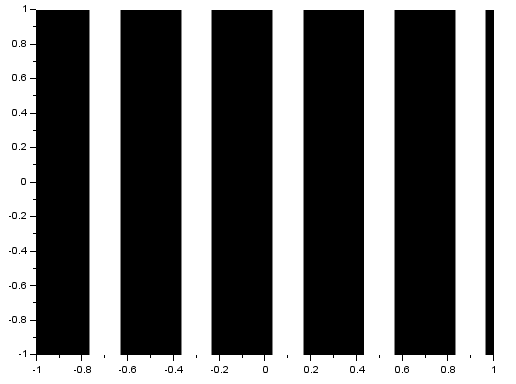
As we know, the FT space is in inverse dimension. Because of this, performing the FT on an image with an object that is wide in one axis will result in a narrow pattern in the spatial frequency axis [1]. As examples, I will show the FTs of different patterns. I implemented the FT in Scilab using the functions given in (Fourier Transform Model of Image Formation). For a tall rectangular aperture:
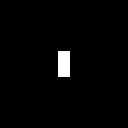

The FT is the image in the right. For a wide rectangular aperture:


We can see that the resulting rectangles in the y-axis for the wide rectangle are narrower than that of the tall rectangle. On the x-axis, we can see that the resulting rectangles are shorter for the tall rectangle. For two dots along the x-axis:


For two dots with a different separation distance:


We can see that the wider the space between the two dots is, the narrower the space between the peaks of the resulting sinusoid pattern (also, the higher the frequency).
B. Rotation Property of the Fourier Transform
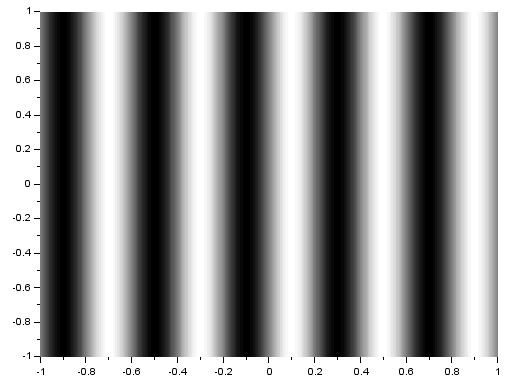
Next, I will investigate the rotation property of the 2D FT where rotating a sinusoid results in a rotated FT [1]. The following images are of sinusoids and their resulting FTs:








The generated matrices used for these images have negative values. Since digital images have no negative values, these sinusoids are not perfect. Because of this, we see multiple dots in the FTs although they were expected to have only two dots which identify the sinusoids’ frequency. Still, we can observe the anamorphic property of the FT. We can see that the resulting dots farther from the center are produced for sinusoids which have closer peaks. To correct the sinusoids, I applied a constant bias so that all values are positive. I got the resulting sinusoid and its FT:


Now we can see fewer dots. The central dot comes from the applied bias. Given a signal or pattern, we can measure its actual frequency by performing the FT and measuring the distance of the two dots from the center. After applying a non-constant bias (a very low frequency sinusoid) to the sinusoid, I got:


If we look closely, we can see two dots near the central dot. These dots represent the frequency of the non-constant bias. If it is known that the bias has a very low frequency, the frequency of the signal can still be measured using its FT.
After rotating the sinusoid, I got:


We can see that the resulting FT pattern rotated as well. Then, I created a pattern formed by adding a sinusoid along the x-axis and a sinusoid along the y-axis. Both sinusoids have the same frequency. I got:


As expected, there are four dots in the resulting FT pattern. Two dots placed on the x-axis and two dots placed on the y-axis. When i multilpy the two sinusoids instead, I get:


The product of two sinusoids along the same axis is given by the following equation [2]:
![\sin u \sin v = \frac{1}{2}[\cos(u - v) - \cos(u + v)]](https://s0.wp.com/latex.php?latex=%5Csin+u+%5Csin+v+%3D+%5Cfrac%7B1%7D%7B2%7D%5B%5Ccos%28u+-+v%29+-+%5Ccos%28u+%2B+v%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
We can see that the product is equivalent to the difference of two sinusoids with frequencies formed from the difference and sum of the frequencies of the original sinusoids. This adding and subtracting of frequencies could be the reason for the position of the dots in the resulting FT.
Finally, I added multiple rotated sinusoids to the previous pattern and performed the FT. I got:


Looking closely, we can see dots around the central dot and they actually form a circle. These dots represent the frequency of the 10 rotated sinusoids that I used. This further proves that a rotated sinusoid also has a rotated FT.
C. Convolution Theorem Redux
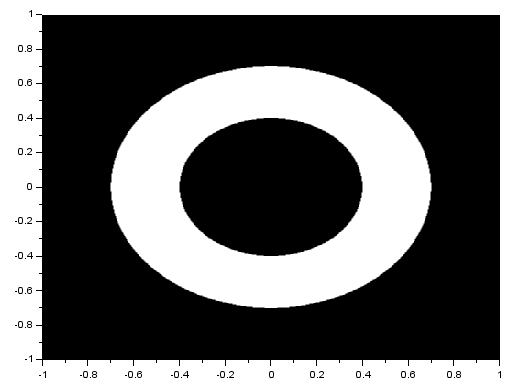
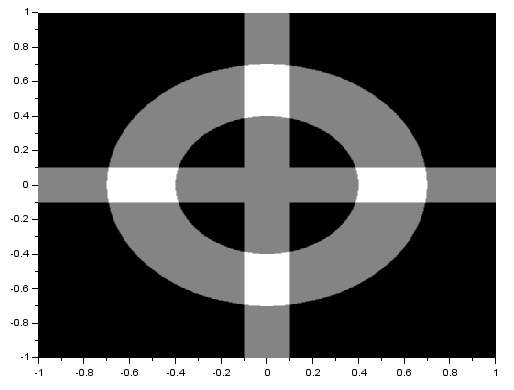
I performed the FT on an image with two circles along the x-axis:


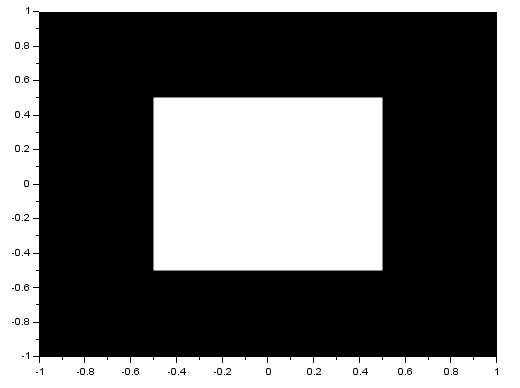
We know that the FT of two dots is a sinusoid and that the FT of a circle is composed of rings. Noting that, we see that the resulting FT here resembles the product of the FT of two dots and the FT of a circle. I also performed the FT on an image with two squares and got:


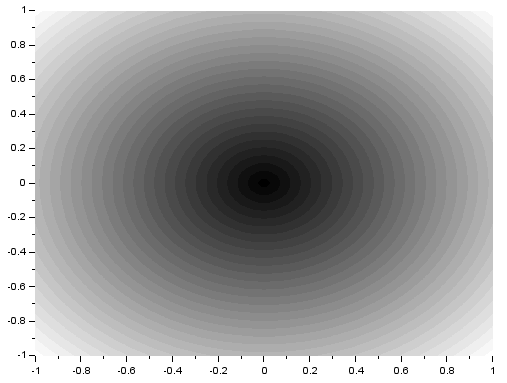
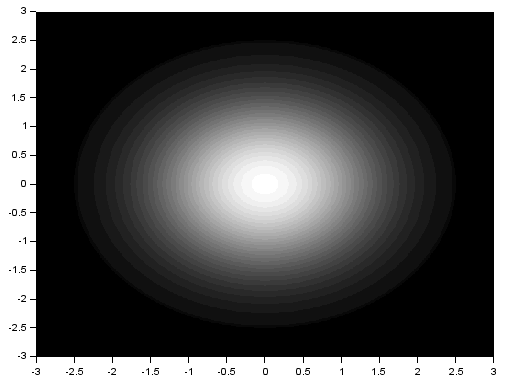
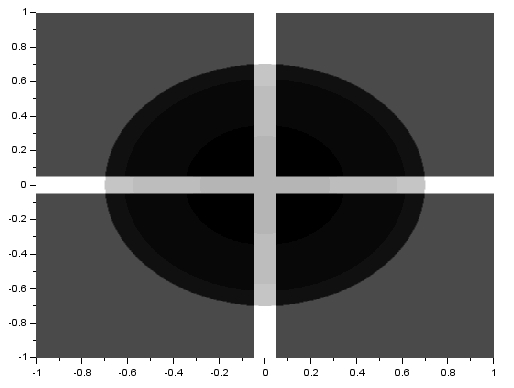
Again, the resulting FT looks like the product of the FT of two dots and the FT of a square. Using two Gaussians of different  , I got:
, I got:








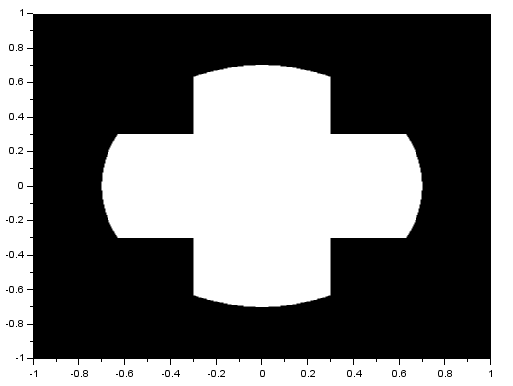
We recall that the FT of a Gaussian is also a Gaussian. Again, the resulting FT looks like the product of the FT of two dots and the FT of a square. From the three previous results, we can observe that the inverse FT of the product of the FT of two dots and the FT of another pattern results in a replication of the pattern at the position of the dots. This, in fact, demonstrates the convolution theorem [1]:
![FT[ f * g] = FG](https://s0.wp.com/latex.php?latex=FT%5B+f+%2A+g%5D+%3D+FG&bg=ffffff&fg=404040&s=0&c=20201002)
A dot in a 2D image actually represents a dirac delta function. We know that the convolution of a dirac delta and a function f(t) replicates f(t) in the location of the dirac delta. Knowing this, we can apply it using an image containing dots and an image containing a distinct pattern. I convoluted a 3×3 pattern which forms a cross (x) with the following image:

and got:

We can see that if we invert x and y in the resulting image, the cross pattern will appear at the location of the points. The axes were inverted because quadrants are shifted when using the fft2() function in Scilab.
Next, I performed the FT on equally spaced dots, with a different spacing for each image:






The second batch of images are the resulting FTs for each corresponding image. For each FT, the sinusoids produced by the multiple dots must have accumulated to form dots with a different spacing. Again, we can observe the anamorphic property of the FT. Knowing the appearance of the FT’s of different patterns, such as this, can be used in constructing filters for image enhancement.
D. Fingerprint: Ridge Enhancement
Next, lets apply the convolution theorem to enhance images. I took an image of my fingerprint, turned it to grayscale, and binarized it.



We can see that there are some areas with blotches and light areas. I took the FT of the grayscale image and got:

We can see that there is a distinct ring. This ring must represent the frequencies of the ridges of my fingerprint. Knowing this, I constructed the filter:

I multiplied this filter with the FT and performed an inverse FT. I got the resulting enhanced fingerprint and binarized it using the same threshold.


We can see that the ridges are now more distinct and the blotches have been reduced.
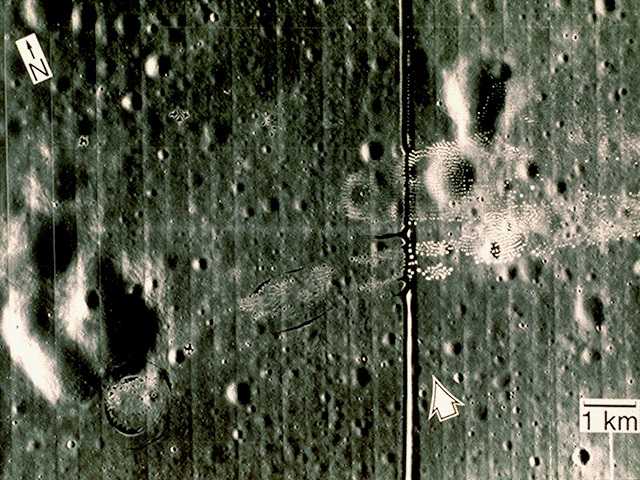
E. Lunar Landing Scanned Pictures: Line removal
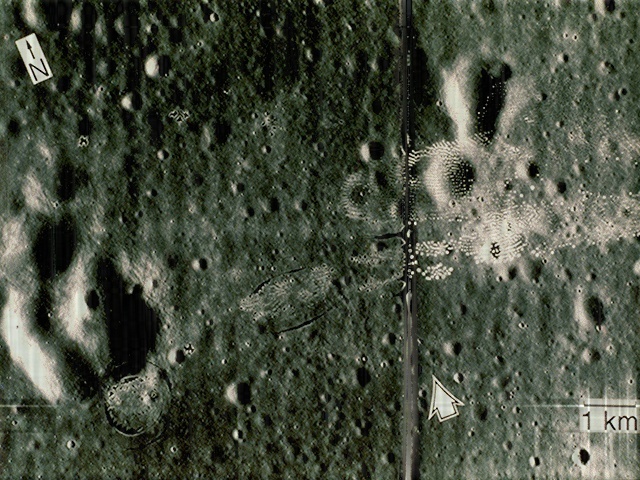
I applied the same method to the image:
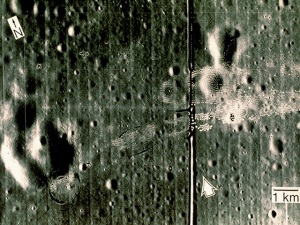
We can see that there are vertical lines throughout the image. It’s not obvious but there are also horizontal lines. I took its FT and got:

Looking closely we can see that there are several dots along the x and y axes. These must represent the frequencies of the vertical and horizontal lines. I constructed the following filter:
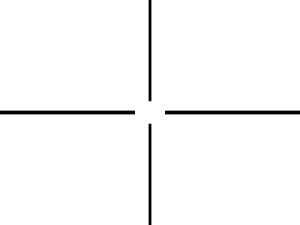
After doing the same thing as in part D, but instead on the RGB components, individually, and then forming the colored image again, I got:
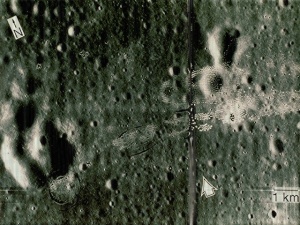
We can see that the vertical and horizontal lines have been removed.
F. Canvas Weave Modeling and Removal
For a final application, let’s look at the image:
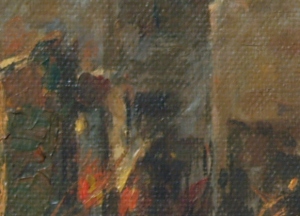
We can see the weave patterns of the canvas. I performed the FT on the image and got:

We can see some dots along the x and y axes and four more dots that form the corners of a rectangle. These dots must represent the frequencies of the weave patterns. I then constructed the filter:
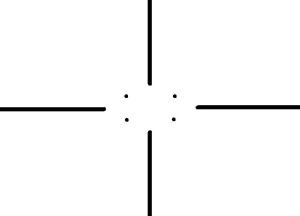
After applying the same method as in part E, I got:
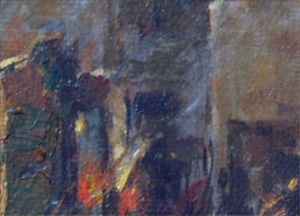
We can see that the presence of the weave patterns has been significantly reduced. To check the filter I used, I took the inverse FT of the filter’s inverse and got:

We can see that it resembles the weave pattern in the painting. Using the convolution theorem by multiplying the inverse of the FT of the pattern we want removed (the filter) with the FT of the image, and then taking the inverse FT is an easy way of enhancing images.
This activity was very long but was very fun to do especially when I actually tried to enhance images. Although there are many more applications in using the FT, I feel like this is some sort of culmination of all the practice done in the previous activity and even of the required study we did on the Fourier Transform in our math and physics subjects. Since I was able to produce all the required images, I will rate myself with 10/10.

References:
- M. Soriano, “A6 – Properties and Applications of the 2D
Fourier Transform,” Applied Physics 186, National Institute of Physics, 2014.
- ” Table of Trigonometric Identities,” S.O.S Mathematics, 2015. Retrieved from: http://www.sosmath.com/trig/Trig5/tritacg5/trig5.html
Image Reference:
http://mrwgifs.com/squall-rinoa-zell-victory-poses-in-final-fantasy-8/




















 51.2.
51.2.


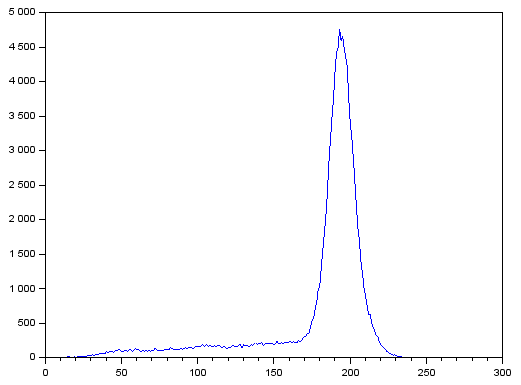






 . Since
. Since 
 ,
,  , and standard deviations
, and standard deviations  ,
,  can be computed [1]. The probability is then computed using the equation:
can be computed [1]. The probability is then computed using the equation: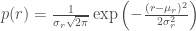





















































































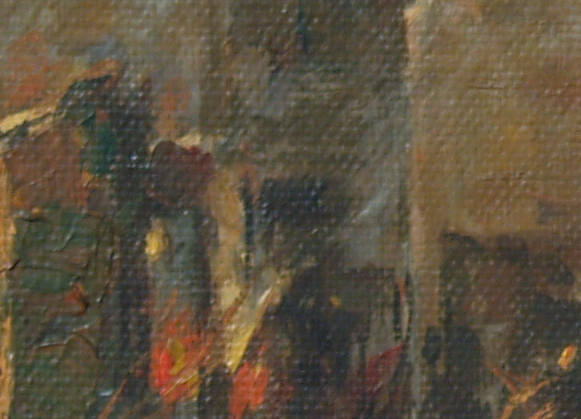



 and
and 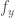 are the spatial frequencies along
are the spatial frequencies along 






















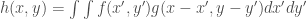
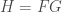






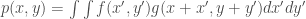












![A = \frac{1}{2}\sum\limits_{i=1}^{N_b}[x_i y_{i+1} - y_i x_{i+1}]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cfrac%7B1%7D%7B2%7D%5Csum%5Climits_%7Bi%3D1%7D%5E%7BN_b%7D%5Bx_i+y_%7Bi%2B1%7D+-+y_i+x_%7Bi%2B1%7D%5D&bg=ffffff&fg=404040&s=0&c=20201002)










{kind=link}